
Ao ler o artigo sobre Inteligência Artificial neste blog, um colega me propôs um desafio diferente: Estimar o valor de ATR (Açúcar Total Recuperado) para uma safra de cana de açúcar. Eu disse que se ele me disponibilizasse uma base de dados histórica de valores de ATR e atributos que pudessem ser correlacionados a este valor eu conseguiria fazer a previsão dos valores.
Mas o que é um ATR?
Os melhores algoritmos serão sempre o produto do trabalho combinado de um Engenheiro de Dados e de um Especialista no Assunto (SME, Subject Matter Expert em inglês).
O SME conhece as necessidades do negócio e suas particularidades, mas geralmente possui uma habilidade menor na exploração de dados e na criação de algoritmos, já o Engenheiro de Dados consegue correlacionar variáveis e gerar algoritmos, mas conhece o negócio superficialmente e precisa de ajuda para interpretar valores e resultados.
O ATR representa o índice de açúcar extraído por tonelada de cana colhida. Além do TCH (Tonelada de Cana por Hectare), este índice é um indicador de extrema importância na Indústria Sucroalcooleira e que determina ações e estratégias de negócio, como por exemplo: quando será a melhor época para colher e qual será meu potencial produtivo. O ATR é influenciado por variáveis como tipo do solo, variedade da cana, data da colheita, clima entre muitas outras.
Iniciei o trabalho abrindo as bases de dados junto com um especialista no assunto no ArcGIS Pro para ter um entendimento inicial das variáveis que formavam tanto a base de dados histórica e a base de dados a ser prevista.
Toda a análise exploratória realizada neste exercício foi executada no ArcGIS Pro. Análise exploratória é o método pelo qual o Engenheiro de Dados passa a conhecer os dados por seus conteúdos do ponto de vista estatístico, e neste caso também geográfico, as correlações e relações topológicas valores das variáveis disponíveis, ou seja, como influenciam umas às outras.
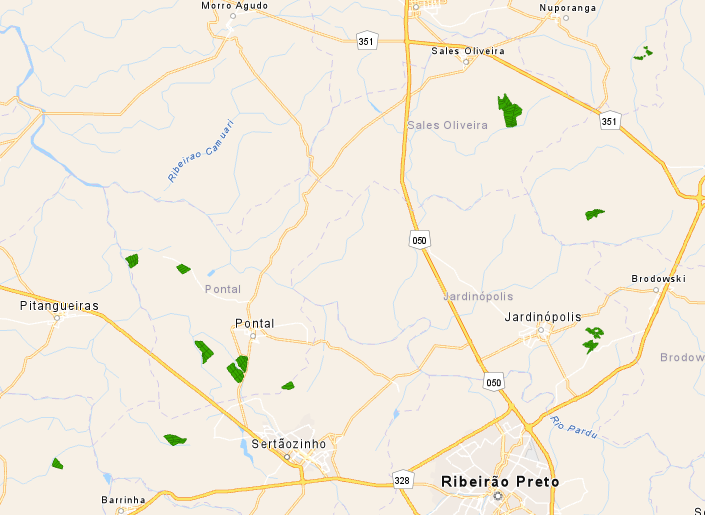
Mapa para visualização da distribuição espacial dos talhões de produção de cana.
Como o componente geográfico tem sempre grande importância para nós, iniciamos nossa exploração de dados com a visualização do dado no espaço. A simples visualização do dado no mapa já nos permite insights.
Ao visualizar em um mapa do ArcGIS Pro a distribuição da nossa amostra de talhões, podemos perceber que nosso DataSet está concentrado na Região de Ribeirão Preto, entre Sertãozinho, Barrinha, Pitangueiras, Sales Oliveira, Nuporanga e Brodowski. Uma região com características de clima e topografia semelhantes. Para este exercício não consideramos variáveis climáticas, modelos de elevação ou declividade.
Como queremos estimar um valor a partir de um conjunto de variáveis e valores de referência, vamos utilizar um algoritmo supervisionado de Machine Learning de regressão.
Algoritmos supervisionados são aqueles que treinamos a máquina passando um conjunto de variáveis e valores de referência. A máquina é treinada com este conjunto de variáveis e é testada com outro conjunto de dados para mediar a assertividade do algoritmo gerado. Depois de treino e teste, o algoritmo entra em produção.
Explorando o ATR
Neste estudo, o ATR é o valor que queremos estimar. O primeiro passo foi visualizar a distribuição estatística e determinar quais variáveis, dentro das disponíveis, seriam usadas para a geração do algoritmo, ou seja, aquelas que estão disponíveis e possuem influência sobre ele.
É necessário que estas mesmas variáveis estejam disponíveis no momento no cálculo do ATR em produção. Algumas variáveis como “Nome da Fazenda” ou “Código Identificador do Talhão” claramente não possuem influência sobre ele, estas e as demais que segundo o SME não influenciam foram descartadas para uso pelo algoritmo.
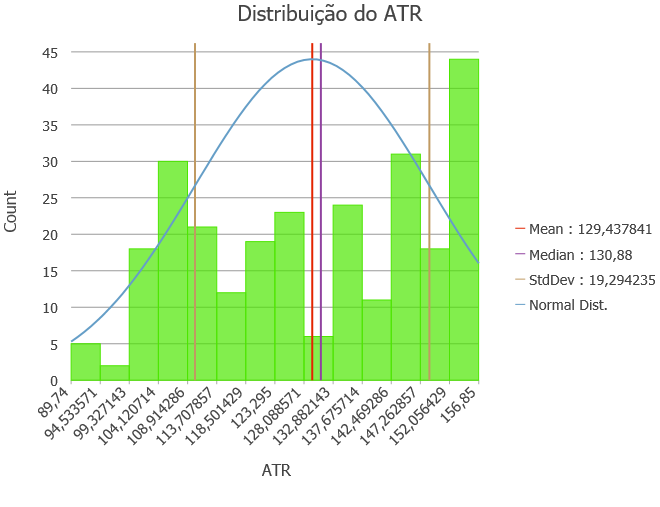
Histograma de ATR gerado pelo ArcGIS Pro.
Ao gerar o histograma da distribuição dos valores de ATR, fica evidente o descolamento em relação distribuição normal, quase uma inversão. O histograma apresenta também uma média próxima a mediana, provavelmente indicando que não existem muitos valores “outliers”.
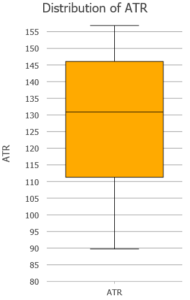
Usando o ArcGIS Pro para gerar gráficos de Box Plot, podemos confirmar esta hipótese. Além destes valores é possível identificar no gráfico acima os valores máximo e mínimo, assim como o desvio padrão.
De fato, o gráfico de Box Plot para o ATR não apresenta “outliers” e confirma a mediana próxima da média. Continuando a explorar o ATR, vamos gerar o Box Plot por safra.
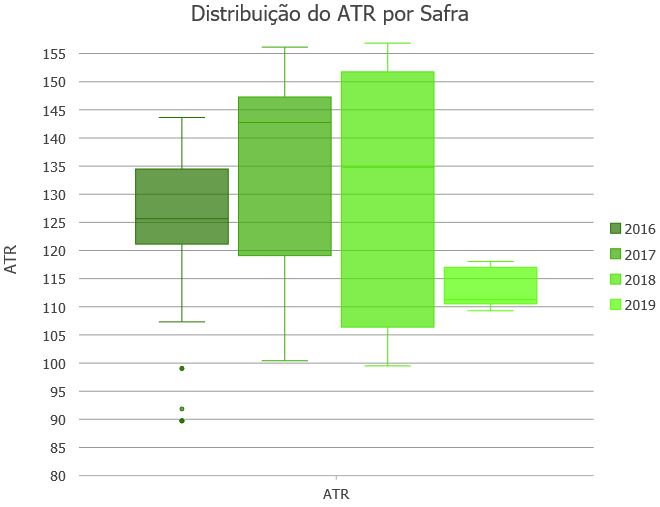
Gráficos de Box Plot gerados no ArcGIS Pro.
Ao separamos no Box Plot o ATR por safra, podemos perceber que a safra de 2016 apresenta alguns “outliers” (os pontos logo abaixo do primeiro box plot), podendo indicar que condições adversas fora da normalidade (queimadas, enchentes, ou clima atípico) podem ter contribuído para estes “outliers”. Como esta safra foi a primeira colheita nestes talhões pode indicar também questões no processo produtivo que foram corrigidas posteriormente.
Fique por dentro de todas as novidades do Portal GEO. Faça grátis sua inscrição!
Veja também:
Transformando dados em informações com OLAP
Inteligência Artificial na Plataforma ArcGIS
5 mitos sobre Location Intelligence
eBook: Inteligência Artificial aplicada aos negócios – BAIXE GRÁTIS!
Baseline
Como baseline, vamos considerar as previsões dos próprios especialistas no assunto, que, segundo informação, possuem um erro de 5% a 10% entre o previsto e o realizado. Nosso objetivo passa a ser além de gerar um algoritmo para a previsão do ATR, mas que possua um erro pelo máximo de menor que o baseline.
Mesmo que possamos simplesmente repetir o mesmo erro do especialista no assunto, as vantagens de se ter um algoritmo simulando a inteligência do SME (justamente a própria definição de AI, a máquina simulando um comportamento humano) é a da repetição, criação, teste de hipóteses e cenários automatizados.
Podemos, por exemplo, atualizar diariamente as variáveis que influem no ATR e automaticamente atualizar previsão. Ou ainda, criar cenário e testar hipóteses. É claro que as previsões serão comparadas com a produção e eventualmente novas variáveis poderão compor o algoritmo em um segundo momento, aumentando sua assertividade.
Conhecendo as variáveis
Com o conjunto de variáveis de interesse determinado, o segundo passo foi estudar do ponto de vista da qualidade de dados, se os conteúdos destas variáveis poderiam ser usados para a geração de um algoritmo de predição de ATR.
O resultado desta primeira análise foi que todos os registros que possuíam uma destas variáveis com valor nulo, foram retirados da base de referência. Outra ação possível poderia ter sido a atualização destes registros pelo especialista no assunto, ou mesmo por um valor padrão.
Além da coleta destes valores pelo SME, o que seria muito custoso, ou do uso de um valor padrão, poderíamos calcular estes valores ausentes usando algoritmos de Machine Learning, ou ainda simplesmente poderíamos eliminar toda a coluna de atributos caso muitos valores nulos fossem observados e descartar a variável.
Neste caso e ainda considerando que não eram em grande número, optei por simplesmente retirar estes registros que possuíam valores nulos para atributos de interesse da base de dados. Como nosso intuito é justamente fazer uma previsão para o ATR, os registros que possuíam o atributo valor do ATR como nulo e com safra para 2019, foram separados para criar nosso Dataset de predição, ou seja, onde iríamos preencher o atributo do ATR com nosso valor calculado para uma colheita ainda a ser realizada.
Registros que possam ter forte influência negativa ou positiva em um resultado, mas que sejam considerados como eventos de exceção podem também ser excluídos, no nosso caso, se tivéssemos a informação de influências de desastres como queimadas, secas ou enchentes, poderíamos retirar estes registros da base para ter valores sem a influência de exceções. De outro modo, este poderia ser justamente o objetivo da análise e neste caso estes registros permaneceriam.
Outra etapa da engenharia de dados para enriquecer nosso Dataset de referência foi derivar novas variáveis das variáveis já existentes permitindo uma correlação mais adequada entre estes atributos e o ATR.
No nosso caso, derivei a partir das datas de plantio e da última ação realizada no talhão (que usei como referência para data de colheita) cinco diferentes e novos atributos: mês de plantio, número da semana no ano de plantio, mês de colheita, número da semana no ano de colheita e o número de dias entre colheita e plantio. Deste modo passo a ter diretamente na base de dados a influência para o ATR das épocas de plantio e colheita da cana assim como o tempo decorrido entre os eventos de plantio de colheita da cana.
O mesmo procedimento com as datas foi realizado no Dataset destinado à predição dos valores do ATR, pois o algoritmo gerado precisa ter o mesmo conjunto de atributos no qual foi criado (base de dados de referência) para ser aplicado em um conjunto de dados de produção.
Do mesmo modo que um atributo pode ser derivado em diferentes atributos, em alguns casos diferentes, atributos podem representar o mesmo dado. Nas bases que usei haviam atributos que representavam o código, nome e descrição de uma mesma informação, como por exemplo tipo de solo. Neste caso, apenas um dos atributos foi considerado, pois representa a mesma influência sobre o ATR.
Outra questão em relação as variáveis é entender o tipo que representam, por exemplo, se representam valores numéricos ou classes. Em relação às variáveis do tipo classe, podemos analisar, por exemplo, quantas ocorrências de uma mesma classe existem no conjunto total de dados.

Gráficos de barras de Contagem de Variedade de Cana gerado pelo ArcGIS Pro.
Podemos ver no gráfico que as variedades de cana, “Viveiros” e “SP80-3280” não possuem muitas ocorrências no Dataset, 2 (duas) e 5 (cinco) ocorrências respectivamente.
Todas as outras variedades possuem 9 (nove) ocorrências ou mais. Duas, cinco, ou mesmo nove ou vinte uma ocorrência podem não ser suficientes para o treinamento do algoritmo. O Dataset que estamos usando é apenas uma pequena amostra e vamos desconsiderar alguma ação neste momento, mantendo estes registros no nosso exercício.
As ações mais recomendadas seriam de usar um Dataset maior com mais ocorrências destas variedades ou mesmo retirá-las do nosso Dataset. Quando tiramos uma variável categórica do treino do algoritmo de ML, significa que não poderemos realizar regressões e classificações com bases de produção que apresentem a variável, ou seja, se tirarmos os registros de “Viveiros” e “SP80-3280” não poderemos prever o ATR para bases que possuam estas categorias.
É claro que neste caso, já estou considerando que a Variedade da Cana terá influência no algoritmo gerado pelo Machine Learning. É uma possibilidade que o algoritmo não use alguma variável, neste caso somente as variáveis com influência identificada pelo algoritmo precisam estar no Dataset de produção.
Para os atributos numéricos, vamos realizar as análises individualmente considerando estatísticas e gráficos por variável numéricas. Como exemplo, vamos observar a variável que apresenta o número de dias entre a data de colheita e a data de plantio. Assim como no caso das variáveis categóricas na exploração de dados estas análises são feitas para cada uma das variáveis.

Análise estatística do tempo em dias entre colheita e plantio gerado pelo ArcGIS Pro.
As variáveis numéricas ainda nos permitem outro tipo de análise, que é a correção entre os valores. Para isso, no ArcGIS Pro, contamos com gráficos de Scatter Plot e Scatter Plot Matrix como os gráficos abaixo.

Scatter Plot Matrix gerada pelo ArcGIS Pro.
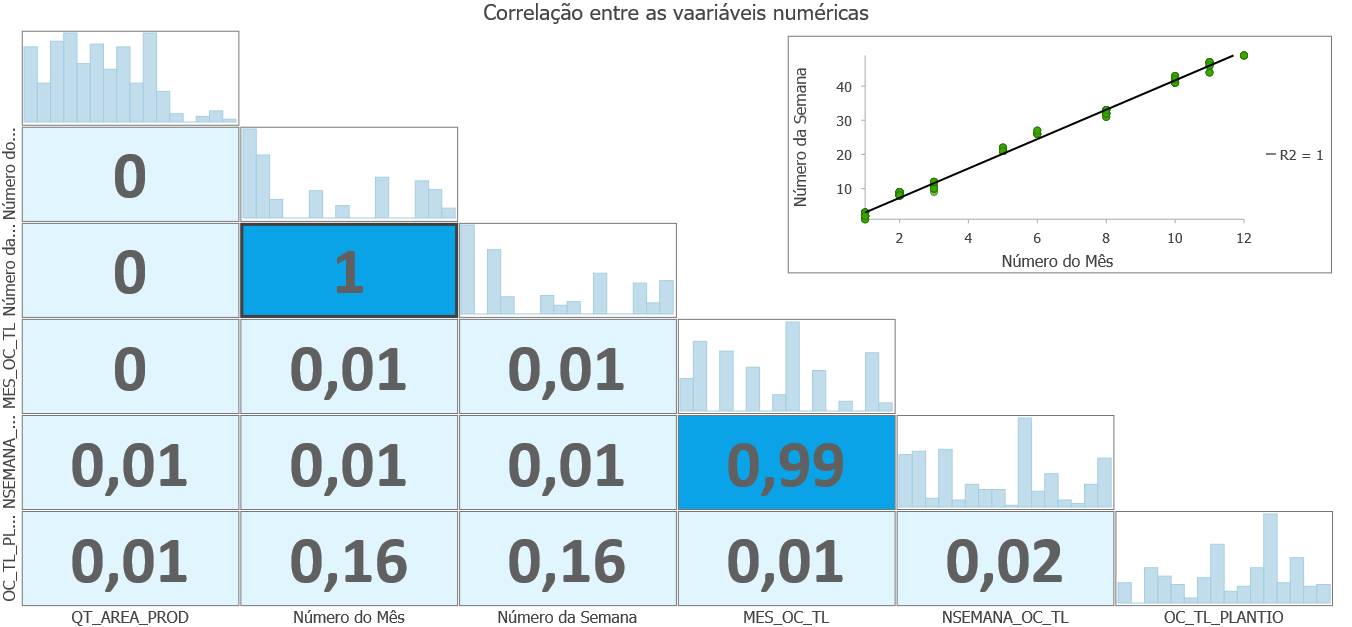
Scatter Plot Matrix com coeficiente de variância R2 gerada pelo ArcGIS Pro.
Fica evidente em ambas as matrizes a forte correlação entre número do mês de plantio e o número da semana de plantio, assim como para colheita. De modo a ter um algoritmo mais performático o possível, vamos considerar apenas uma destas variáveis. Já que são muito correlacionadas provavelmente terão a mesma influência no algoritmo.
Voltando ao nosso caso, existe grande correlação entre o número de semana no ano, número do mês do ano tanto para plantio como para colheita. Sendo assim, vamos usar apenas o número da semana de plantio e o número da semana de colheita, deste modo reduzimos em duas variáveis a complexidade do algoritmo a ser gerado.
Por fim, depois de reduzir registros com dados nulos, derivar variáveis e descartar variáveis (por indicação do SME, redundância ou correlação), chegamos ao Dataset (atributos e registros) que serão considerados para a geração do algoritmo de ML que usaremos para a predição. Precisamos agora gerar o algoritmo, vamos a ele.
Para gerar o algoritmo, a ferramenta do ArcGIS Pro usada será Forest-Based Classification and Regression.
A figura abaixo representa o uso da ferramenta para treinar o algoritmo de Machine Learning para predizer o ATR. É necessário informar que será realizado apenas o treino (Train Only), a base histórica de variáveis, qual variável será o objeto da regressão (ATR) e o conjunto de variáveis escolhidas para o algoritmo (Tipo do Solo, Variedade da Cana, Número da Colheita, Ambiente Produtivo, Ambiente de Manejo, Número da Semana no Ano de Plantio, Número da Semana no Ano de Colheita e o Número de Dias entre Colheita e Plantio).
Além destas informações, deve-se deixar desmarcado o campo “Treat Variable as Categorical” para que o algoritmo não funcione como classificação, neste caso queremos uma regressão. Também é possível informar como (percentual de registros para teste) queremos distribuir a base em percentuais entre treino e teste.

Ferramenta usada para a criação do algoritmo de ML para a regressão do ATR.
Quando executada a ferramenta apresentará metadados da execução como o número de árvores e tamanho das folhas da Floresta de Árvores de Decisão gerada. Também apresentará o MSE (Mean Square Error ou Erro Quadrático Médio em português). O MSE representa a média dos erros (diferença entre valores previstos e valores reais na base de teste) elevados ao quadrado. Quanto menor o valor deste erro melhor. A raiz quadrada deste erro está na mesma dimensão do valor predito.

Outras informações importantes são o quanto as predições, tanto em treino como em teste, estão correlacionadas com os valores observados, os metadados abaixo podem apontar que o modelo está em “overfitting” por exemplo, quando o acerto em treino é muito maior que em teste. Não é o caso do nosso exercício.

Os modelos baseados em árvore de decisão possuem uma saída muito relevante para os SMEs que aponta para a influência de cada uma das variáveis no valor da predição.
O gráfico abaixo mostra que o número da semana de colheita tem a maior influência sobre o ATR quando comparado com as demais variáveis. Eventualmente uma das variáveis pode-se tornar extremamente mais influente que as demais ao ponto de dominar totalmente o algoritmo, nestes casos pode-se executar o treinamento do algoritmo sem esta variável para observar a influência das demais.
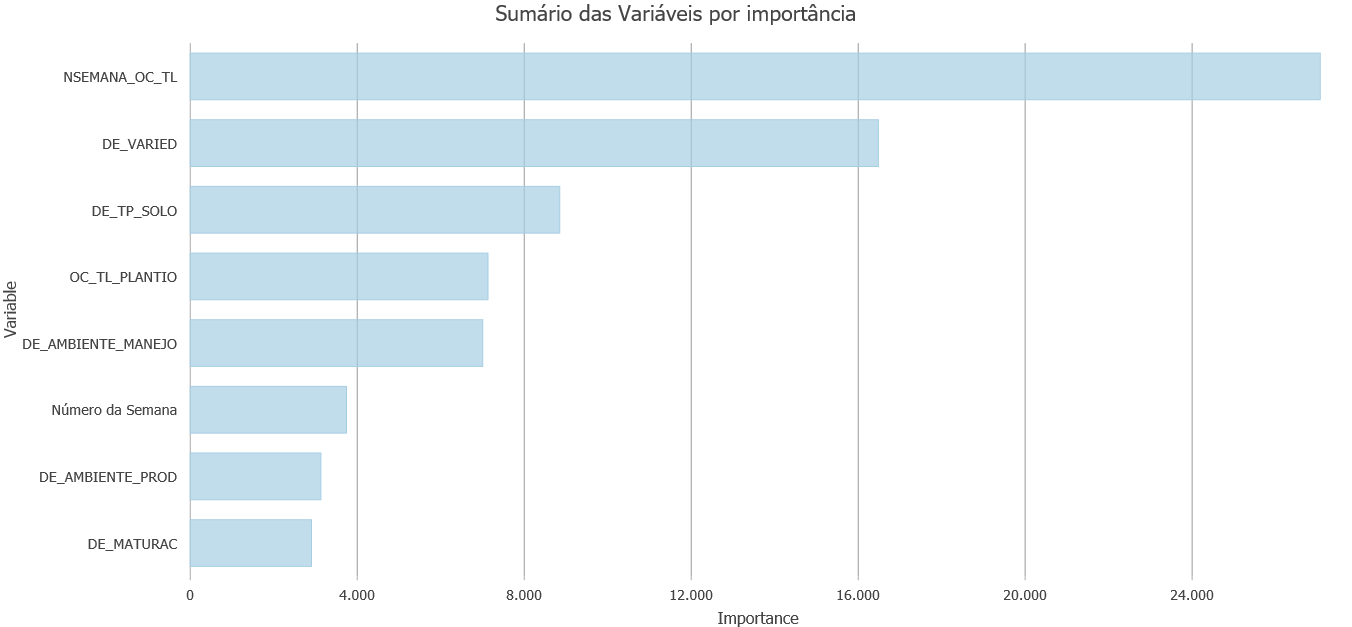
Sumário de Variáveis por importância na decisão.
Uma vez que o algoritmo está treinado e se está satisfeito com o resultado do treinamento, troca-se a opção “Prediction Type” de Train Only para Predict to Features e altera-se o valor do percentual de registros usados para teste para 0%. Executa-se então o modelo passando o DataSet que será usado para a predição e o que será gerado com a predição de valores.
Resultado final

Resultado final no ArcGIS Pro.
A figura cima apresenta o algoritmo de Machine Learning treinado e executado no DataSet de previsão de ATR. Uma camada com os talhões para a safra 2019 foi inserido com as variáveis usadas e um atributo de ATR Previsto.
A ferramenta do ArcGIS Pro ainda permite que dados raster e relações topológicas com dados vetoriais sejam considerados diretamente como variáveis pelo modelo. Neste caso usamos apenas os atributos associados às geometrias de talhões como variáveis para o algoritmo de Machine Learning. Também não consideramos neste caso variáveis climáticas, mas certamente podemos associá-las às variáveis usadas para ter um modelo melhor.
Conseguimos treinar e testar um algoritmo de Machine Learning, com erro bem aceitável em relação ao baseline, para realizar a previsão do ATR para a safra 2019. Vamos agora esperar a safra e ver como foram nossas previsões.
Agradeço ao Marlon Suenari da Imagem e ao Hermogenes Machado da Biosev por serem os especialistas no assunto, sem os quais, os números não fariam sentido.
Você gostou desse artigo?
O Portal GEO está sempre trabalhando para trazer novidades, tendências e o que há de melhor em dicas do universo GIS. Clique abaixo e faça sua inscrição gratuita para receber com comodidade todos os nossos artigos, que tenho certeza, vão te apoiar em seu cotidiano profissional e pessoal, te deixando sempre bem informado:

IA Aplicada ao ArcGIS
Comece a extrair a entender como o ArcGIS pode potencializar a Inteligência Artificial
Falar com especialista