
Agricultura de Precisão (AP) é uma estratégia de gestão que reúne, processa e analisa dados temporais, individuais e espaciais e os combina com outras informações para apoiar as decisões de gerenciamento de acordo com a variabilidade estimada para melhorar a eficiência no uso de recursos, produtividade, qualidade, rentabilidade e sustentabilidade da produção agropecuária (ISPA, 2018).
As primeiras iniciativas de adoção e pesquisa da AP no Brasil ocorreram na segunda metade da década de 1990. Mas foi a partir do ano 2000, com a eliminação do ruído no sinal de GPS pelos EUA, que houve um boom nas aplicações práticas e pesquisas acadêmicas sobre AP.
Desde então, essa área de conhecimento, vem evoluindo vertiginosamente em função dos avanços no desenvolvimento de hardwares, softwares e técnicas computacionais.
Neste âmbito, o presente artigo tem como objetivo discorrer sobre um tema que tem sido bastante discutido atualmente na área de AP, a delimitação de Zonas de Manejo, e como podemos utilizar os recursos do ArcGIS Pro realizar este procedimento de forma automatizada.
O que são Zonas de Manejo?
O conceito de Zonas de Manejo (ZM), trata sobre a subdivisão dos campos de produção em áreas menores de forma que a produção potencial, a eficiência do uso de insumos e risco ambientais sejam relativamente homogêneos, garantindo que a variabilidade dentro de cada área subdividida seja menor do que a variabilidade entre elas (Luchiari et al., 2000).
Esta divisão é feita ao combinar os dados de diversas variáveis, coletadas em diferentes momentos, que tenham influência direta na variabilidade da produção, e posteriormente separar as regiões que tenham características semelhantes.
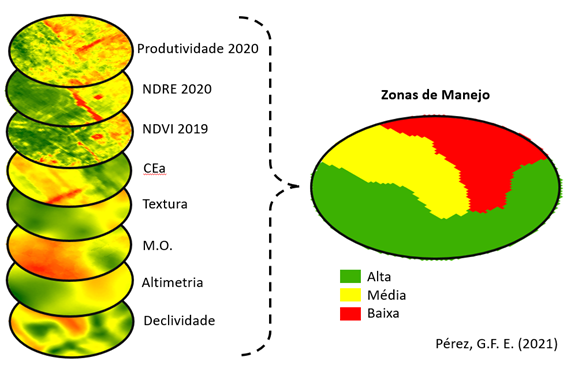
Não se trata de um conceito novo, pois é possível encontrar aplicações práticas nos EUA a partir 1995, como os trabalhos realizados por Luchiari Junior et al. (2000), Shanahan et al. (2000) e Fraisse (2001).
No entanto, o aumento das discussões sobre a aplicabilidade deste conceito no Brasil deu-se em função da percepção de que as técnicas que vinham sendo utilizadas na primeira década após a introdução da AP (amostragem do solo em grade e a fertilização a taxa variada) não estavam sendo suficientes para a redução da variabilidade do desempenho das culturas nos campos de produção e que a variabilidade poderia ser explicada também pela existência de regiões dentro do campo de produção que apresentam diferentes características além da fertilidade, como relevo, exposição solar, profundidade de horizontes, textura, capacidade de armazenagem de água, entre outras (Schwalbert et al., 2014).
Segundo Miranda (2020), as ZM ganharam destaque também frente ao alto custo que implica o uso de malhas amostrais em alta densidade. Nanni et al. (2011) citam que a maioria das amostragens de solo realizadas comercialmente no Brasil são definidas em função de questões meramente econômicas e utilizam um espaçamento de 2 a 3 hectares por amostra.
No entanto, o estudo realizado por eles mostrou que uma densidade de 1 amostra por hectare não foi suficiente para “capturar” a variabilidade espacial das 3 principais variáveis utilizadas em recomendações de fertilização.
Sendo assim, a delimitação de ZM, passou a ser vista também como uma opção para redução nos custos de produção, por meio da otimização e aplicação racional de recursos e insumos, assim como a simplificação de processos operacionais, uma vez que as intervenções de manejo devem ser dimensionadas e prescritas especificamente para cada ZM considerando os fatores limitantes de produtividade existentes em cada uma delas.
Como posso delimitar Zonas de Manejo?
Diversas metodologias têm sido discutidas na comunidade acadêmica, no entanto, como não existe uma metodologia única formalmente aceita (Miranda, 2020), é desejável que sejam utilizados métodos que permitam reduzir a subjetividade da tomada de decisão, por meio de ferramentas matemáticas e estatísticas que forneçam parâmetros concretos para avaliação dos resultados.
Nesse contexto, a análise de dados multivariados pode ser considerada a mais adequada para a de geração de ZM, devido à sua robustez em termos de estatística e modelagem de dados (Molin et al., 2016, citado por Diel, 2018).
A análise multivariada de dados se refere à todas técnicas estatísticas que analisam simultaneamente múltiplas variáveis de indivíduos ou objetos sob investigação. Assim, qualquer análise simultânea de mais de duas variáveis pode ser considerada análise multivariada (HAIR et al., 2010, citado por Diel, 2018).
Dentre as diversas técnicas de análise multivariada mais utilizadas na delimitação de ZM em AP, está a análise de agrupamentos, ou clusterização. Trata-se de uma técnica utilizada para agrupar elementos a partir de características em comum.
Para esta etapa do processo de delimitação de ZMs, o ArcGIS Pro disponibiliza a ferramenta Multivariate Clustering, que fornece duas opções de algoritmo para realizar o agrupamento de dados: o k-means e o k-medoids.

O k-means, ou k-médias, é um algoritmo iterativo que classifica objetos em uma quantidade “k” de grupos (clusters), previamente definidos. Ele tem como função de classificação a distância do objeto ao centróide do grupo em que a soma de todas as distâncias euclidianas entre cada objeto e o seu centróide seja minimizada.
O método k-medoids, ou k-medoides, é bem semelhante ao k-médias, a principal diferença está em que no k-médias o centróide não precisa pertencer ao conjunto de dados e no k-medóides o centro é um dos pontos do conjunto (medóide).
De acordo com Galambošová et al. (2014), o método de clusterização mais utilizado na delimitação de ZMs é o método k-médias, no entanto, Soni & Patel (2017) relataram em seu trabalho que o método k-medoides teve um desempenho superior tanto na velocidade de processamento quanto na acurácia da classificação. Além disso, o este método é menos suscetível à presença de outliers nos dados.
No entanto, nem tudo são rosas. O grande na utilização de ambos os métodos, pode-se citar dois pontos de atenção: o desafio em definir o número ideal de clusters em que os dados serão agrupados e a definição de quais variáveis são realmente relevantes para que o agrupamento seja realizado de forma ótima e significativa.
Com relação à definição da quantidade de agrupamentos (clusters), de acordo com SUSZEK et al. (2012), métodos empíricos utilizados na definição da quantidade de ZMs geralmente apontam a utilização de três ou quatro agrupamentos.
No entanto existem métodos paramétricos para chegar na quantidade ótima de agrupamentos, como o “método do cotovelo” utilizado por Oliveira et al. (2017) para definir o valor de “k”.
No caso do ArcGIS Pro, a ferramenta Multivariate Clustering permite gerar uma tabela com os valores da pseudo-estatística F para soluções com 2 a 30 clusters.

Os maiores valores da pseudo-estatística F indicam soluções que têm melhor desempenho na maximização das semelhanças dentro de cada cluster e das diferenças entre eles.
Com relação à definição das variáveis mais relevantes para o processo de clusterização, outra técnica de análise multivariada muito utilizada no processo de delimitação das ZMs é Análise de Componentes Principais (ACP), que permite definir quais são as variáveis mais relevantes a serem utilizadas no processo de clusterização.
A ACP é uma técnica que tem como principal objetivo reduzir a dimensão de análise de conjuntos de dados associados a variáveis quantitativas correlacionadas entre si.
A ACP permite identificar as variáveis que explicam a maior parte da variância total contida em conjuntos de dados, além de explicitar relacionamentos que podem existir entre variáveis ou entre observações de uma população ou de uma amostra (Jolliffe, 2002, citados por Fontana, 2017).
Na ACP, são realizadas transformações matemáticas a partir das variáveis originais, que resultam em um novo conjunto de variáveis sintéticas denominadas componentes principais (CPs). As CPs são ordenadas de modo que as primeiras componentes retêm a maioria da variabilidade presente no conjunto de dados original (Gavioli, 2017), e desta forma, pode-se selecionar somente as informações que tem alta relevância no processo de clusterização.
Para esta etapa, o ArcGIS Pro disponibiliza a ferramenta Principal Components, que executa a ACP em um conjunto de “n” imagens e resulta em uma imagem única, com “n” bandas, em que cada banda condensa as informações de cada CP, sequencialmente e ordenadamente. Sendo assim, a banda 1 da imagem resultante corresponde à primeira CP e retém a maior parte da variabilidade.
De acordo com a ESRI, frequentemente, as primeiras três ou quatro bandas da imagem resultante descrevem mais de 95% da variação, e por isso as bandas restantes podem ser desconsideradas em posteriores análises.
De acordo com Ferreira (1996), citado por Gavioli (2017), devem ser consideradas as primeiras CPs que, juntas, expliquem ao menos 70% da variabilidade total das variáveis originais. Sendo assim, ao selecionar as 3 primeiras bandas da imagem resultante, teoricamente estaríamos selecionando as informações mais relevantes para o processo de clusterização.
Para confirmar se a seleção da quantidade de CPs está correta a ferramenta Principal Components, permite gerar um relatório de qualidade onde pode-se verificar a porcentagem acumulada de autovalores.
Autovalores, ou Eigenvalues, são valores que representam a contribuição relativa de cada CP na explicação da variação total dos dados.
No exemplo acima, as 3 primeiras bandas descrevem aproximadamente 74% da variabilidade dos dados e poderiam ser submetidas ao processo de ACP descartando as outras 7 bandas, sem prejuízos na qualidade do processo de clusterização.
Como integrar as ferramentas do ArcGIS Pro para obter a delimitação das Zonas de Manejo de forma automática?
Como não existe uma ferramenta pronta para delimitação de ZMs no ArcGIS Pro, é preciso utilizar os recursos disponíveis no sistema para criação de scripts e desenvolvimento de ferramentas personalizadas. Para tanto, o ArcGIS Pro disponibiliza os recursos do Jupyter Notebook, de forma totalmente integrada.
O Jupyter Notebook é um ambiente de programação, para linguagem python, que oferece uma abordagem do tipo “Notebook”, com um visual simples e intuitivo, e permite organizar os códigos de programação por meio de marcações via linguagem “Markdown”.
Sendo assim, para exemplificar a construção de uma ferramenta que gera ZMs automaticamente, utilizando os recursos do ArcGIS Pro, criei um script no Jupyter Notebook que integra as ferramentas de análise multivariada. A seguir são mostrados, passo a passo, os trechos de código que permitem executar todo o processo de geração de ZM automaticamente.
Conforme apresentado na figura abaixo, a primeira célula do notebook foi destinada à importação das bibliotecas necessárias para execução do script.

Já a segunda célula, foi destinada à criação das variáveis de entrada e dos parâmetros que serão aplicados nas ferramentas de análise multivariada.

A pasta de dados de entrada deve conter imagens (raster), de banda única, obtidas a partir da interpolação de dados discretos (fertilidade do solo, produtividade, curvas de nível, levantamentos topográficos, entre outros) ou a partir de dados contínuos (bandas de imagens de satélite, índices de vegetação, MDEs, entre outros).
Para o presente exemplo foram usados dados de fertilidade e textura do solo, dados de produtividade, dados de condutividade elétrica aparente, dados de relevo e índices de vegetação em duas safras diferentes. Como parâmetro de entrada, foi informado o diretório onde encontra-se a feição do tipo “polígono” que delimita a área de interesse.

Para a quantidade de CPs, definiu-se que seriam selecionadas as 3 primeiras componentes e posteriormente o número seria validado com os resultados presentes no relatório emitido pela ferramenta Principal Components.
Para a quantidade de clusters a serem criados, foi informado o valor “0”, para que o próprio ArcGIS defina o valor de “k” s a partir dos valores da pseudo estatística F. Posteriormente, o resultado é validado por meio do gráfico gerado a partir da tabela resultante do processamento da ferramenta Multivariate Clustering.
Para o método de clusterização, definiu-se o valor 2 que indica a aplicação do método k-medoides. Este método foi selecionado em função das vantagens citadas anteriormente. Como parâmetro de entrada, definiu-se também o valor de “área mínima”, em hectares, que indica menor valor de área existente na feição resultante após o processo de clusterização.
Na terceira célula, consta o trecho do script que cria uma pasta onde serão salvos os resultados finais do processamento, e complementarmente é feita a limpeza da pasta temporária onde os arquivos temporários são salvos.

A quarta célula do notebook contém o trecho do script que realiza a padronização e redimensionamento das imagens raster de entrada.
A quinta célula do notebook contém o trecho do script que executa a ACP nas imagens raster de entrada e converte o resultado em feições do tipo “ponto”, para posteriormente poder executar a clusterização.

O processamento deste trecho do script tem como resultado complementar o relatório analítico da ACP.

Por meio do relatório, salvo na pasta de resultados, foi possível verificar que 80% da variabilidade dos dados está representada nas 3 primeiras componentes principais, ou seja, nas 3 primeiras bandas da imagem raster resultante.
Sendo assim, a definição de 3 CPs nos parâmetros de entrada trará resultados satisfatórios na próxima etapa (ACP).
A sexta célula do notebook contém o trecho do script que executa o processo de clusterização dos pontos resultantes da ACP. No primeiro trecho de código da sexta célula, primeiramente são definidos alguns dos parâmetros da ferramenta de clusterização, em função de parâmetros informados na segunda célula do notebook e outros que dependem dos resultados da execução de células anteriores. Em seguida executa-se o algoritmo de clusterização em si.

Caso o parâmetro de entrada “Numero de clusters” tenha sido indicado como “0”, o script exporta o gráfico mostrando os valores da pseudo estatística F em função do número de clusters, o que permite verificar qual é a quantidade ótima de clusters. Para este exemplo, de acordo com o gráfico salvo na pasta de resultados, a quantidade ótima de clusters seria de 7 grupos. E é em função deste valor máximo de F que o ArcGIS define quantidade de ZM.

No entanto, no mesmo gráfico é possível verificar que adotar 4 clusters também poderia ser uma boa estratégia, pois assim reduziria-se a quantidade de ZM, sem perda significativa qualidade da clusterização. Sendo assim, o analista poderia rodar o script novamente, mas informando no parâmetro “Número de clusters” o valor 4.
A sétima e última célula do notebook, contém o trecho do script que converte os pontos clusterizados em polígonos, executa uma “limpeza” dos polígonos com área inferior ao valor informado no parâmetro “área mínima” e por fim, limpa a pasta temporária e as varáveis criadas.

Os resultados da subdivisão da área de produção em 4 e 7 Zonas de Manejo, após a finalização da execução de todo o script, podem ser verificados na imagem abaixo.


Para finalizar o presente artigo, gostaria de agradecer a IMAGEM pela oportunidade em discorrer sobre este assunto que vem se mostrando uma tendência na área de Agricultura de Precisão, e também ao Prof. Dr. Lucas Rios Amaral da FEAGRI/UNICAMP, coordenador do Grupo Interdisciplinar de Tecnologia em Agricultura de Precisão (GITAP), que gentilmente me permitiu cursar 2 disciplinas do programa de pós-graduação ministrada em 2021, nas quais obtive a base teórica e prática necessária para discorrer sobre o assunto e desenvolver o script disponível neste artigo.
O notebook e o código comentado estão disponíveis em meu GitHub, como forma de retribuição à comunidade pela a oportunidade que me foi dada.

Fique por dentro de todas as novidades do Portal GEO. Faça grátis sua inscrição!
Você também pode gostar:
Aplicação de Técnicas de Deep Learn e Pytorch para Censo em Plantio Florestal 90 dias
EBook: Os 25 anos de Geoprocessamento da SEDU / PARANACIDADE
INDI Maps – Plataforma de Site Selection para Atração de Investimentos em Minas Gerais
Planejamento urbano com qualidade para os municípios paranaenses

IA Aplicada ao ArcGIS
Comece a extrair a entender como o ArcGIS pode potencializar a Inteligência Artificial
Falar com especialista